Guardrails
Tests, rules and constraints to stay in control.
Introduction: from architecture to method
In the previous chapters (The Context Odyssey), I tested several ways to load and pass context to agents. I ended up returning to something more pragmatic once I saw the direct impact on code.
I had a clear constitution and well-maintained instruction files. On paper, everything looked solid. In code, it was different: the AI generates, and sometimes it gets things wrong. I needed guardrails, not promises.
The daily question was still there: how do we work with agents without falling back into over-engineering? This chapter explains how I put quality rails in place so each iteration gives immediate feedback.
State of play
At this stage, I already use these tools every day. My setup includes:
- reusable prompts (commands, skills);
- a single project constitution (shared rules and frame);
- an orchestrator that can launch agents and close the loop with sub-agents;
- a robust CI that only lets PRs through when tests and build are green;
- scripts and symbolic mappings to generate context files for multiple tools.
I move between architecture, technical steering, and tooling. I still write code, but mostly to harden the automation ecosystem.
The real issue was no longer adding more instructions. It was making quality verifiable.
Towards quality assurance and orchestration tools
From there, I looked for a simple signal: the AI proposes, the system responds. If something breaks, I want clear feedback and a way to fix it immediately. The goal is not to train the model through longer prompts, but to put limits in the code.
We often talk about DX (Developer Experience) for humans. I talk about AIX: the same idea, but for AI systems. When I configure a linter, an error message, or a script, I do it so an AI can understand and self-correct. If feedback is clear, it moves forward. If feedback is vague, it loops and repeats mistakes.
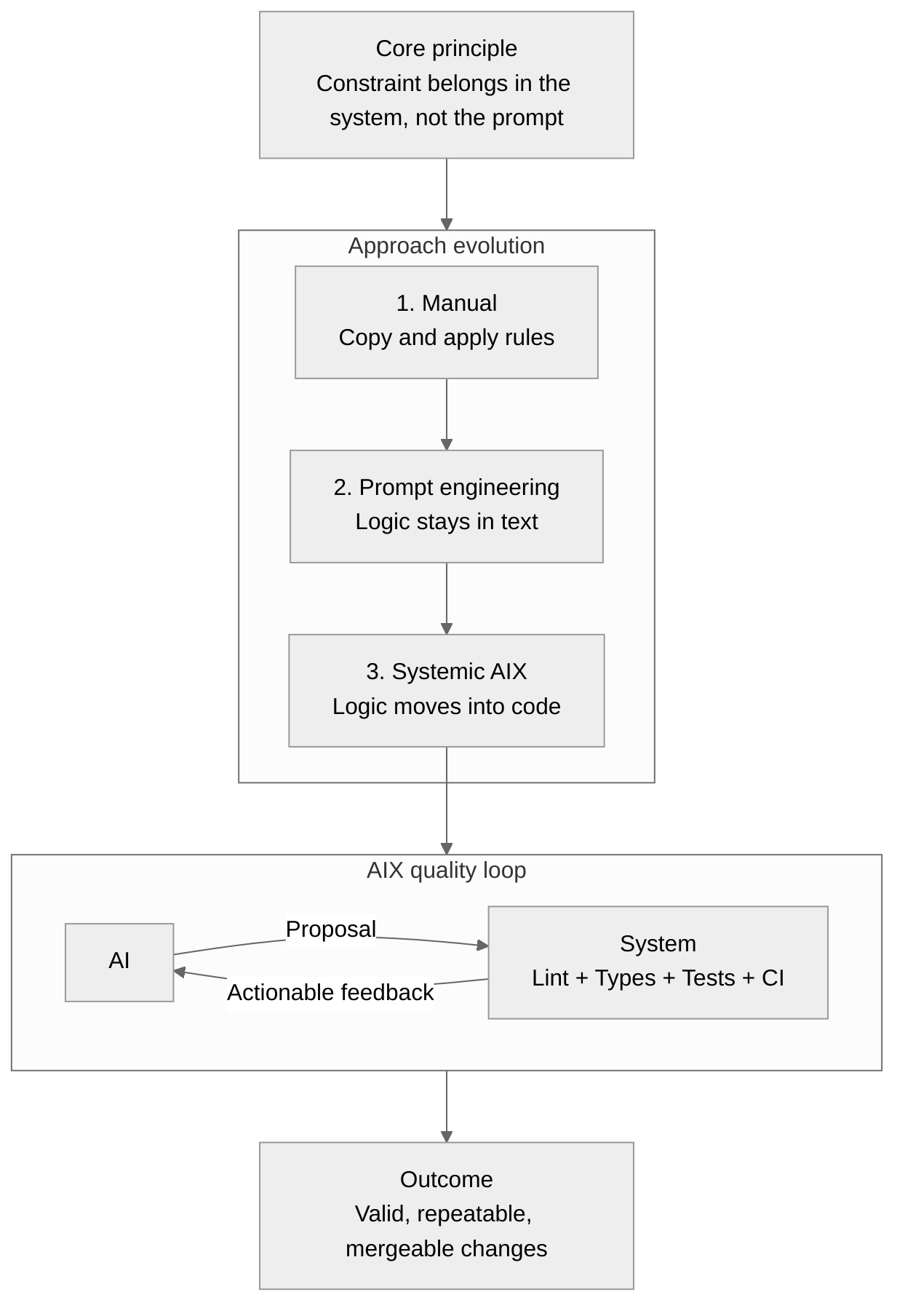
The operational loop (from prompt to guardrails).
- I define the task (usually in simple terms).
- The AI plans and explores the codebase, finds existing patterns, proposes an implementation.
- It edits the code and runs local tests (tooled scripts).
- It saves and commits through Git.
- My hooks and pipelines trigger automatically: linters, type checks, architecture rules, unit and integration tests.
- Feedback goes back to the AI (logs, errors, diffs), which fixes and tries again until validation.
- CI reruns the same set of checks (plus heavier ones) before authorizing PR/merge.
Concretely, this is what I put in place:
- Automated linting and formatting triggered locally and in CI;
- Strict type checking (TypeScript strict mode);
- Automated architecture rules (Dependency Cruiser);
- Unit and integration tests designed for agent workflows;
- Git hooks that notify agents and trigger analyses and suggestions;
- CI pipelines that run advanced checks and surface tickets/actions.
Note (today): my workflows kept evolving. I now have hooks that trigger as soon as a file is written or edited in Claude Code (lint/typecheck). Feedback is faster, but less complete than commit-time and CI checks.
I cleaned up and published the architecture validator as open source: hex-validator. It is built for my architecture choices, but its rules and patterns can still be useful.
The idea is simple: let the AI propose, but force proposals through a system that validates, blocks, or returns actionable feedback.
The next chapter covers a longer stabilization phase, where these guardrails are tested on real projects.