Orchestrating the Essential
Orchestrating agents, from workflow to sub-agents.
Autumn 2025 — agent orchestration
Changing posture
For years, my pleasure was “eating code”. That remains true. But today, code alone is no longer a differentiator: we can all code, and AIs too. What matters to me is thinking through the need: deciding what to do, what we automate, how we control. The AI does not replace the developer: it amplifies the developer’s posture. If the mindset is “I pilot, I check, I orchestrate”, models become reliable accelerators. If the mindset is “I copy/paste”, they become debt generators.
I dedicated hundreds of hours to testing. Sometimes I pushed too far, sometimes I backtracked. It is not a hole in my CV: it is an investment. I build, I observe, I adjust. AI changes how I learn and try things; it doesn’t think for me, it accelerates me. And that naturally led me to orchestrate rather than writing everything myself.
Why agent orchestration
When Claude Code introduced sub-agents with separate context (dedicated window, own tools/config) that execute, render a report then start from zero, I first wanted to “do things right”. The very next day after the release, I create a meta-agent whose sole role is to read the official doc… and generate other agents on demand.
In one evening, I find myself with about thirty specialized agents: generalist front-end, “UI state” front-end, “accessibility” front-end, back-end, database, “test diagnostic”, “Playwright tester”, “lint/format”, “CI triage”, “doc writer”, etc.
On paper, it looks like an ideal team. In reality, I recreate the ceremony I was taught in companies: “client → PO → architect → dev → tester → reviewer → tech lead → human”.
And there, backlash:
- each sub-agent lives in its own bubble and forgets everything once its task is finished;
- if the main agent does not transmit information perfectly to the right agent, we fall into a “telephone game” scenario;
- friction increases (too many steps, too many messages), quality drops (info loss, repetitions, misunderstandings).
I realize that I fell into the trap of over-organization. I wanted to create an ideal team, I created a bureaucracy.
I then understand that multiplying agents is not enough. The stake is not to have 30 executors, but to have a coherent overall vision and explicit rules of the game.
I trim the fat to get back to basics:
- fewer agents, well cut;
- the main agent clearly resuming its role of orchestrator;
- my role: setting the rails (perimeters, rules, validations, order of passage) and intervening at the right moment.
Open question (beyond AI): if too many ceremonies end up hurting signal quality between agents, aren’t we sometimes reproducing the same drift in some human organizations that became “too agile”?
My orchestration workflow (mid-October 2025 version)
Over the course of these trials, I converged towards something much simpler:
- fewer agents, more guidance,
- a single main “orchestrator”,
- and two very simple commands:
/issueto talk to GitHub (create/update/comment on issues),/worktreeto create parallel working copies (one per sub-task).
I tested a very advanced approach with lots of scripts, logs, end-to-end tests… then I dropped it: too fragile, too complicated for the value it brought.
Today, orchestration fits in a single reusable prompt (command/skill): a text that describes the expected workflow, the steps, the possible actions and when to call /issue or /worktree.
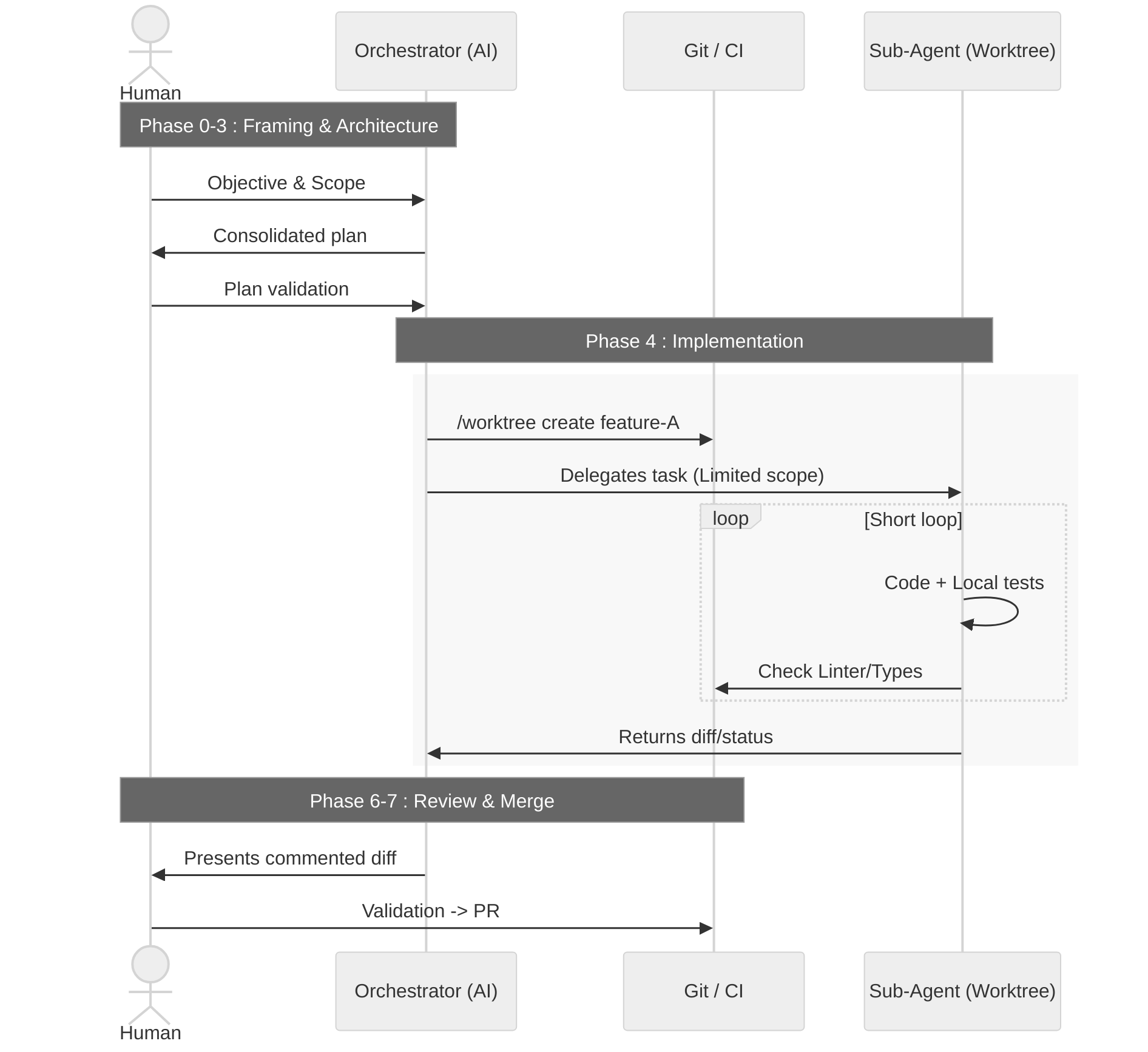
My orchestration workflow looks like this:
- Phase 0 — Human ↔ orchestrator alignment. We agree in a few messages on the objective, the scope, and what “finished” means.
- Phase 1 — Targeted exploration. The orchestrator reads the project, scans the documentation and test signals, and summarizes for me what it understood.
- Phase 2 — Refining with the human. It asks me the right questions again, we adjust constraints, we settle ambiguities.
- Phase 3 — Architecture. The orchestrator proposes one or several approaches (sometimes involving 1–2 specialized “architects”), then submits a consolidated plan to me.
- Phase 4 — Implementation.
- For a simple task: a single agent works in a dedicated working copy.
- For a complex task: the orchestrator cuts into sub-tasks, creates several working copies and delegates to several agents, each on their piece.
- Phase 5 — Tests. Tests, lint, type and architecture checks are launched on the agent side; problems are corrected in a short loop.
- Phase 6 — Review. The orchestrator presents me with a commented diff; I reread, I comment, I ask for corrections if needed.
- Phase 7 — PR. A pull request is created with the context, a checklist, and a link to the concerned issues.
The key principles remain simple:
- few agents, just specialized enough;
- a breakdown of work and context;
- explicit contracts between steps;
- the least friction possible (enough to guarantee quality, no more);
- observable
/issueand/worktreecommands (sober logs), but no useless glue code.
Crash‑test of over‑orchestration
Conversely, another project shows me what happens when I go too far in AI orchestration.
In early October, I decide to put everything into sub-commands: management of branches, worktrees, issues, PRs, with hooks, guards, “secure” workflows and scripts that wrap what Git already knows how to do.
On paper, it’s reassuring: everything is framed, everything goes through home-made rails. In practice, I spend days:
- fighting with path and portability problems;
- stacking scripts difficult to debug;
- documenting a complexity that I created myself.
The ratio “energy spent / value created” got bad. This approach was not sustainable over time.
On November 1st, I do a first cleanup:
- I delete dozens of specialized commands;
- I throw away scripts that duplicated Git without real benefit;
- I reduce documentation that was only compensating for complexity.
A few days later, I do a second pass:
- I cut again “skills” and documents, sometimes by 70% or more;
- I formalize simple principles:
- a skill must orchestrate, not describe the whole strategy;
- the agent is supposed to be intelligent, it doesn’t need 800 lines of examples;
- we start small, we delete what doesn’t serve;
- we iterate on real needs, not on “just in case”.
This repository becomes for me concrete proof that:
- too much abstraction can cost more than what it brings;
- documentation is not an antidote to bad architecture;
- the right decision is not always “add a layer”, but sometimes remove a layer.
The related repo is here: claude-code-plugins/orchestration. The repo is maintained, and the workflows keep evolving.