The Context Odyssey
From over-engineering to radical simplification.
Introduction: the “prompt engineering” red herring
At the beginning of 2025, as my projects were growing, I hit the context wall. Models were forgetting rules, inventing patterns, and breaking my architecture. My first reaction was that of an engineer: I wanted to build a rigid control system.
This is where my L0/L1/L2 context architecture idea emerged. It wasn’t just a naming convention; it was an attempt to create a true operating system for AI.
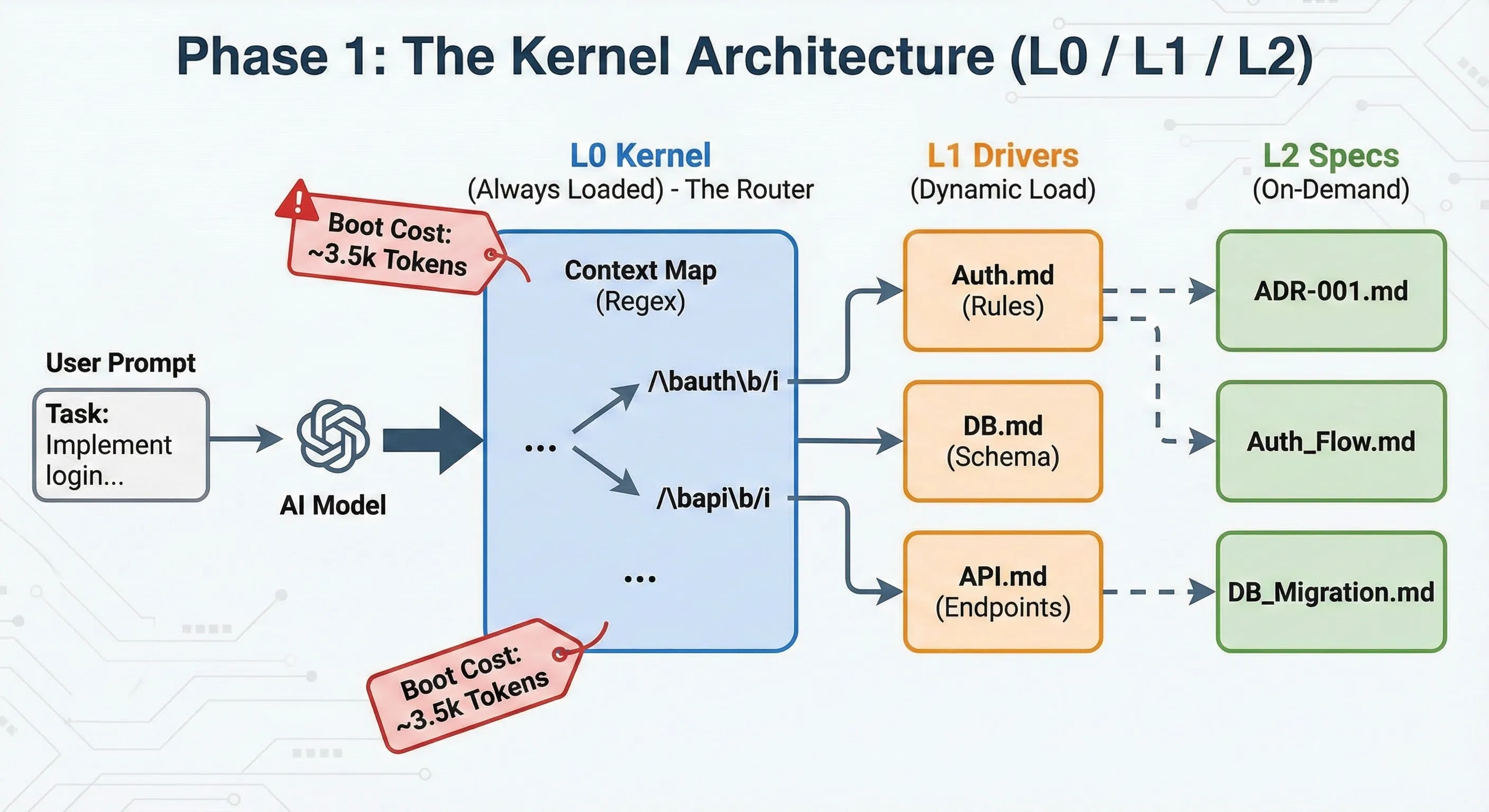
Phase 1: the kernel (L0 / L1 / L2)
The era of centralized control.
I designed a strict hierarchical architecture, inspired by system privilege levels.
- L0 (the kernel): a master file (
L0.md) loaded permanently. It acted as a smart router containing a “context map” based on complex regexes. If the AI detected the wordauth, it knew it had to load the corresponding L1 module. - L1 (the drivers): domain-specific business rules (authentication, database, API). These files contained non-negotiable constraints (
!NEVER commit secrets). - L2 (the specs): detailed technical documentation and ADRs (Architecture Decision Records), loaded only on demand to understand the “why”.
The problem: this approach worked, but at a prohibitive cost. The system “boot” cost about 3,500 tokens for each interaction, just to say “hello”. Furthermore, maintaining the central L0 file became a bottleneck: adding a feature meant modifying the kernel.
Kernel example (L0.md):
# L0 KERNEL (ROOT CONTEXT)
## MISSION
Act as a senior software architect and lead developer. Your goal is to produce maintainable, scalable, and secure code following the project's established patterns. You must orchestrate the loading of specialized contexts (L1) based on the task at hand.
## CRITICAL RULES (THE "NEVER" LIST)
1. **NEVER** commit secrets or credentials.
2. **NEVER** bypass the established hexagonal architecture layers.
3. **NEVER** introduce new dependencies without explicit approval (ADR required).
4. **NEVER** write "spaghetti code" (high cyclomatic complexity).
5. **NEVER** ignore linter or type-checker errors.
## L1 CONTEXT MAP (ROUTING TABLE)
| Priority | Pattern (Regex) | L1 Context File | Description | Load Strategy |
| :------- | :-------------- | :-------------- | :---------- | :------------ | --------------- | ------------------------------ | ----------------------------------- | ----------------------------------- | ---- |
| 1 | `/\b(auth | login | signup | session | jwt | oauth)\b/i` | `L1/Auth.md` | Authentication & Security protocols | AUTO |
| 2 | `/\b(db | database | prisma | drizzle | sql | migration)\b/i` | `L1/Database.md` | Data persistence & schema rules | AUTO |
| 3 | `/\b(api | endpoint | route | controller | trpc | graphql)\b/i` | `L1/API.md` | API design & interface standards | AUTO |
| 4 | `/\b(ui | component | tailwind | css | front)\b/i` | `L1/UI.md` | User Interface components & styling | AUTO |
| 5 | `/\b(test | spec | e2e | mock)\b/i` | `L1/Testing.md` | Testing strategies & standards | AUTO |
## OPERATING PROCEDURE
1. **Analyze Task:** Read the user's prompt.
2. **Scan for Patterns:** Match prompt content against the `L1 CONTEXT MAP` regex patterns.
3. **Load L1 Contexts:** For each match, load the corresponding `L1` file.
- _NOTE:_ L1 contexts provide domain-specific constraints and patterns.
4. **Execute:** Perform the task, adhering strictly to L0 rules AND the loaded L1 rules.
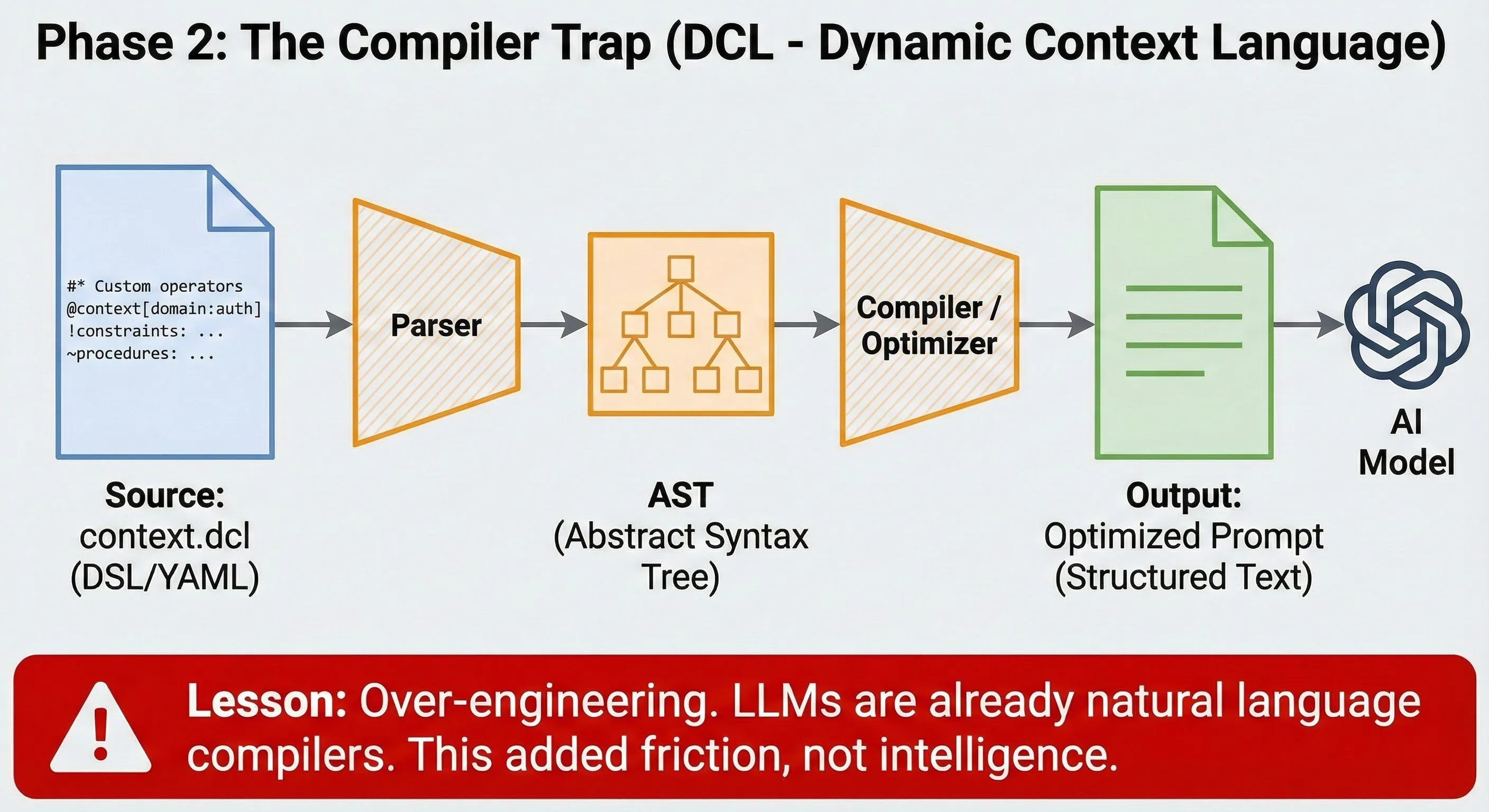
5. **Consult L2 (Optional):** If deep clarification is needed on a specific decision, consult the referenced L2 specs (ADRs) mentioned in the L1 files.Phase 2: the compiler trap (Dynamic Context Language)
When the engineer wants to engineer too much.
Frustrated by the fuzziness of natural language, I swung to the opposite extreme: treating context like code. I created DCL (Dynamic Context Language).
Instead of writing instructions, I wrote specifications in YAML with custom operators:
@context[domain:auth]
!constraints:
never: [commit_secrets, raw_sql]
~procedures:
add_endpoint: [validate, authorize, audit]I even built a compilation pipeline (Source → AST → Optimized Prompt). The productive failure: I realized I was reinventing the wheel. LLMs are already natural language compilers. Forcing them to read pseudo-code added friction without increasing intelligence. It was pure over-engineering.
DCL Example:
# ==========================================
# DCL (Dynamic Context Language) - Example
# ==========================================
# Domain: Authentication Module
# ==========================================
# Defines the global context of the domain
@context[domain:auth]:
# Strict constraints (the AI must NEVER do this)
!constraints:
- never: [commit_secrets, raw_sql_queries]
- enforce: [use_orm, secure_password_hashing]
# Necessary dependencies for this context
^dependencies:
- lib: [bcrypt, jsonwebtoken]
- service: [user_service, email_service]
# Procedures and patterns to follow
~procedures:
# Pattern for user signup
user_signup:
- step: validate_input
desc: "Check password complexity and email format."
- step: hash_password
desc: "Use bcrypt for hashing. Never store in clear text."
- step: create_user
desc: "Call user_service for database creation."
- step: generate_token
desc: "Generate a JWT for the session."
- step: send_welcome_email
desc: "Call email_service."
# Pattern for login
user_login:
- step: find_user
desc: "Search user by email."
- step: verify_password
desc: "Compare hash with bcrypt."
- step: generate_token
desc: "Generate a new JWT."
# Expected data models
#schema:
User:
- id: [uuid, pk]
- email: [string, unique]
- password_hash: [string]
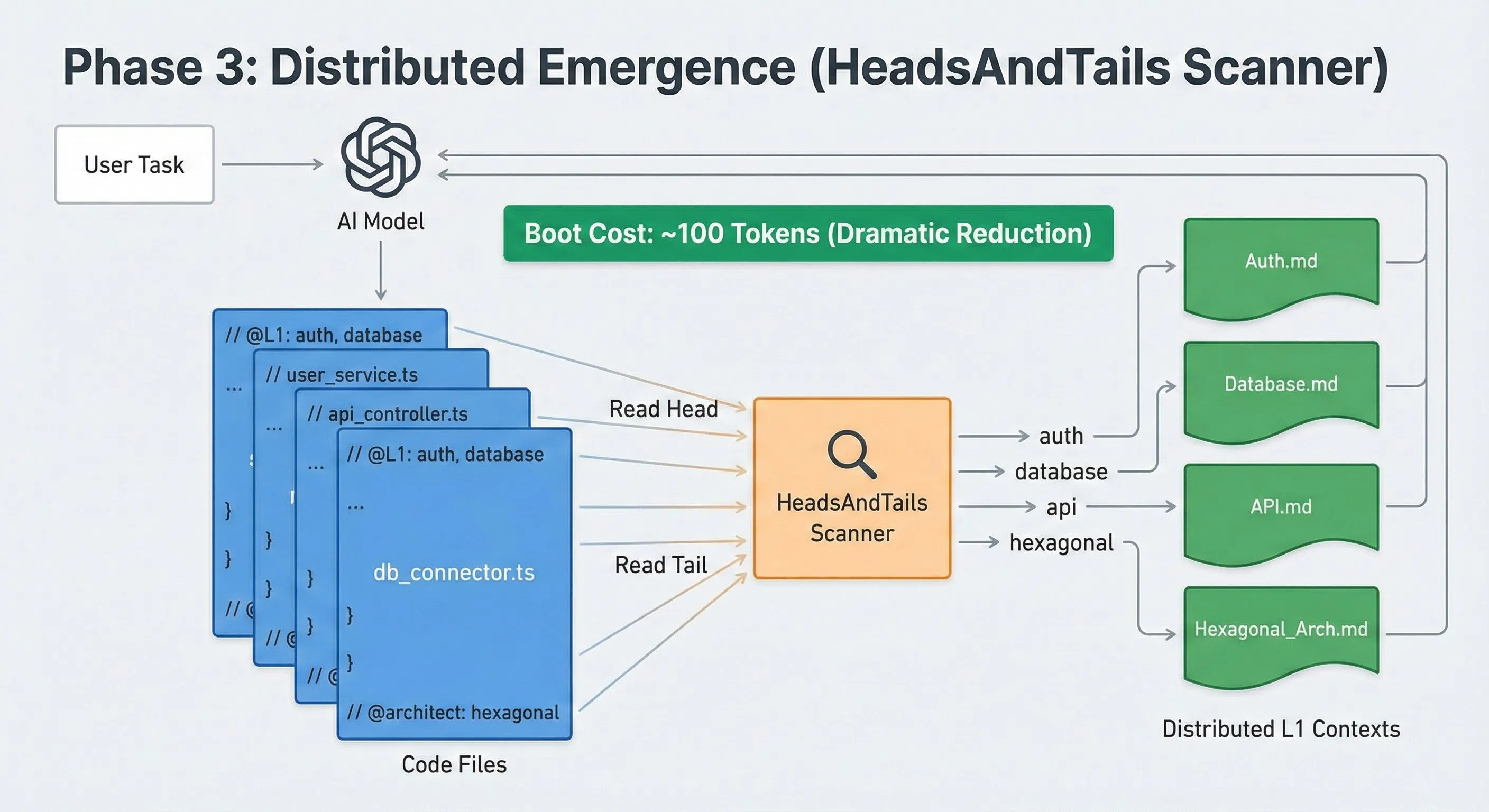
- created_at: [datetime]Phase 3: distributed emergence
Context doesn’t load, it emerges.
I then removed the central kernel for a distributed approach. Instead of a master file that knows everything, each code file declared its own needs via tags, like imports:
// @L1: auth, api.
I developed a lightweight scanner, “HeadsAndTails”, which only read the beginning and end of files to discover these tags.
- Gain: The startup cost dropped from 3,500 to ~100 tokens.
- Philosophy: context is no longer loaded in a centralized way. It is loaded on demand, based on the task and the proximity of the relevant code.
Example file with context tags:
// ==========================================
// FILE: src/modules/user/core/application/use-cases/CreateUser.ts
//
// @L1: auth, database, domain-events
// @architect: hexagonal/use-case
// ==========================================
import { User } from "../../domain/User";
import { IUserRepository } from "../../ports/IUserRepository";
// ... other imports
export class CreateUserUseCase {
constructor(
private readonly userRepo: IUserRepository,
// ...
) {}
async execute(command: CreateUserCommand): Promise<Result<User>> {
// Business logic...
// The AI knows it must respect "auth" and "database" rules
// because they were declared in the header.
}
}
// ==========================================
// @security: low-risk
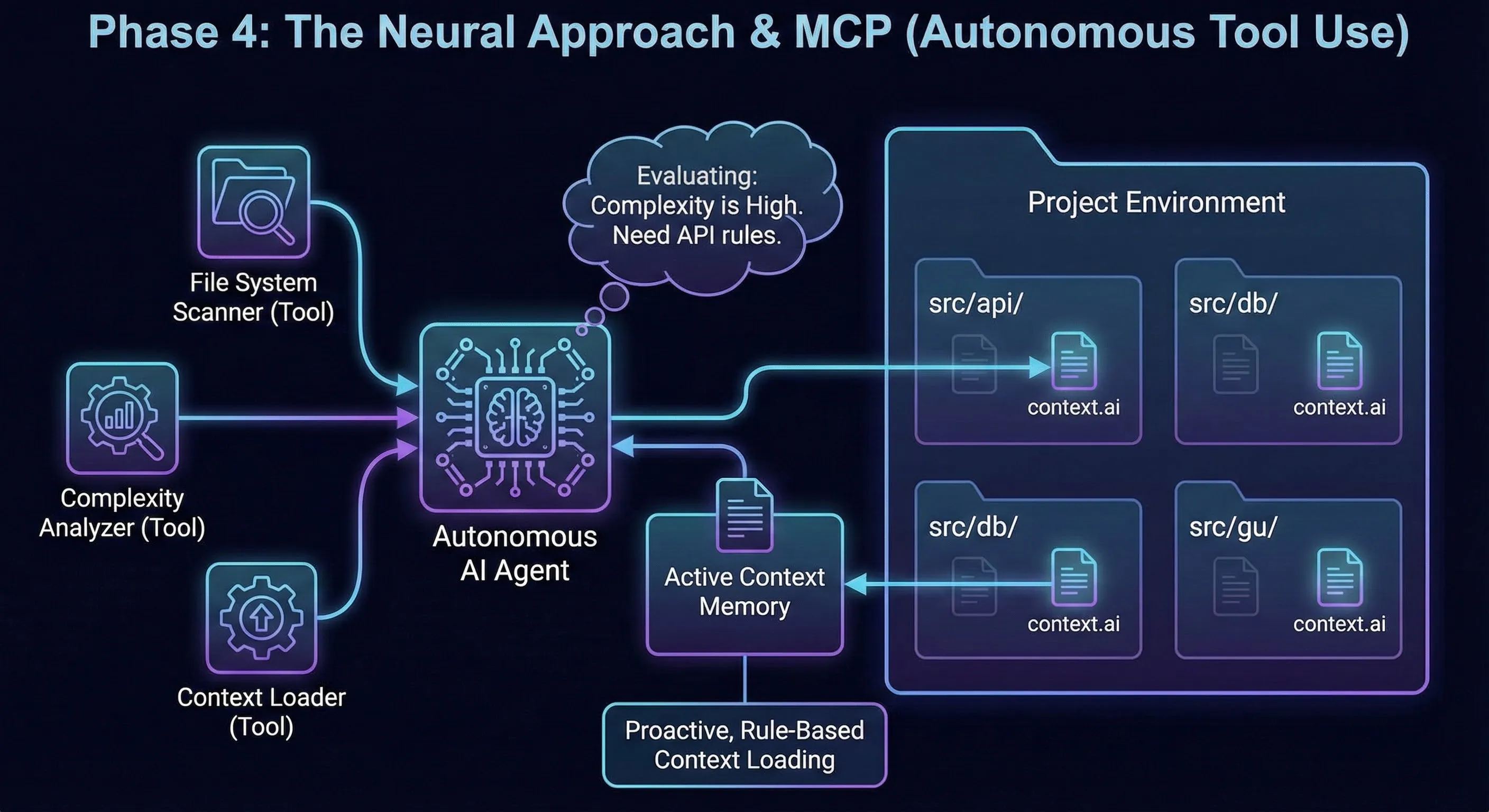
// ==========================================Phase 4: tool-driven lazy loading (AI.md + custom MCP)
From static rules to targeted retrieval.
This phase does not stack on top of the previous ones: I set prior mechanisms aside to test a new context-engineering approach.
I keep a stable base that is always loaded: AI.md. This is the shared constitution across all my agents.
In that file, I define a custom MCP (my tools and their usage rules).
When I open a new chat / agent, that cost is paid once: the MCP definition is injected into the initial context.
After that, loading becomes on demand:
- The agent receives a task (ex: authentication).
- It calls my custom MCP to retrieve relevant context.
- The MCP returns the
context.aifiles tied to the domain and targeted files. - The agent loads only that context, then executes.
The key point: in my case, MCP is used to retrieve and load task-relevant context. That’s what enables on-demand loading.
In hindsight, this was already a form of homegrown RAG.
Context file example (context.ai):
# ==========================================
# LOCATION: src/modules/payment/context.ai
# ==========================================
# Metadata for the agent
meta:
domain: payment
description: "Critical rules for payment processing."
# Conditional loading rules
# The agent evaluates these rules before deciding to load this context.
load_if:
- rule: "Task involves money, transactions, or stripe."
reason: "High risk domain."
- rule: "User explicitly mentions 'payment' or 'checkout'."
reason: "Explicit request."
- rule: "Files being edited are in 'src/modules/payment/'."
reason: "Proximity."
# The context itself, loaded only if a rule is met.
context:
# Critical constraints
constraints:
- "NEVER log full credit card numbers or CVV."
- "MUST use the 'PaymentGatewayPort' for all external calls."
- "All transactions MUST be wrapped in a database transaction."
# Implementation patterns
patterns:
- name: "Idempotency"
description: "Ensure payment requests are idempotent using a unique key."Simulation: the agent with custom MCP in action
User: “I need to refund a payment. It’s sensitive.”
AI (Thought): “Critical task in
paymentdomain. I won’t code anything without checking the rules.” AI (MCP Action):fs_scanner.scan("src/modules/payment", look_for=["context.ai"])AI (Result): “Filecontext.aifound.” AI (MCP Action):context_loader.load("src/modules/payment/context.ai")AI (Thought): “Context loaded. Critical rules: usePaymentGatewayPort, wrap in DB transaction. Ok, I can start the plan.”
Phase 5: return to basics (the constitution)
Maturity and letting go.
Today, I replaced that architecture with a simpler version. Why? Because at the time of these tests, models (Claude 4.0 and later) had become more capable: they were better at finding information and better at understanding context. They no longer needed constant hand-holding; what they needed was a constitution.
My current system fits in a single file: AI.md.
To ensure compatibility with all my tools (Cursor, Windsurf, CLI script), I use symbolic links: CLAUDE.md, GEMINI.md, CURSOR.md all point to this single file.
What the constitution (AI.md) contains:
It is a clear, strict, and pragmatic rule framework:
- The guardrails: a list of NEVER and MUST.
- NEVER throw in domain
- NEVER violate layer boundaries
- Architecture as law: the project structure is not a suggestion. The file strictly defines what each layer has the right to import and how they communicate.
- Drift prevention: rather than giving blind orders, I explain the why.
- “Why do these rules exist? To decouple the domain from technology.”
- By providing meaning, the AI adheres better to the constraint.
Constitution architecture
A single source of truth for all agents, zero duplication.
# Back to basics: Simplicity
$ ls -l .ai/
-rw-r--r-- 1 user staff 4096 Nov 21 AI.md # The constitution (single source)
# Aliases for tool compatibility. They all point to the same file.
lrwxr-xr-x 1 user staff 5 Nov 21 CLAUDE.md -> AI.md
lrwxr-xr-x 1 user staff 5 Nov 21 CURSOR.md -> AI.md
lrwxr-xr-x 1 user staff 5 Nov 21 GEMINI.md -> AI.mdExtract from the constitution (AI.md):
# Constitution
## TL;DR (The "NEVER" List)
**NEVER:**
- Mute lint/type errors (fix root causes)
- Violate layer boundaries (core→npm, application→infrastructure)
- Throw in domain/application (return `Result<T, E>`)
## Principles & Rationale (Drift Prevention)
**Why these rules exist:**
1. **Architecture**: We decouple the _core domain_ from _technology_...
...Conclusion: the lesson of obsolescence
Assessment
I no longer try to “pilot” the AI to the micro-second with compilers or complex routers. I give it a compass (AI.md), a map (the file tree), and I let it navigate.
The code is better, my mind is freer, and the system is finally stable. Less is more.
Reflections a few months later
Rereading this journey a few months later, one thing strikes me: some of these constructions are now obsolete — that is the price of learning in a field that evolves fast.
All this work – the L0 kernel, the DCL compiler, the tag scanner – was swept away by the constant improvement of models and the arrival of new standards. This is the law of this field: we build temporary bridges while waiting for technology to allow us to fly.
But it wasn’t time wasted. It was the necessary learning to understand what really matters: architecture and business constraints.
I cleaned up and published the code from this exploration as open source: ai-context-layers. It’s an educational archive of Phases 1 to 4, not a maintained product, but the patterns and the DCL compiler can serve as inspiration.
What’s next?
My logic has therefore evolved. Since I can no longer (and no longer need to) control everything a priori in the prompt, I focus on validation a posteriori.
My new current undertaking is the creation of a custom validator. Not just a linter, but an engine of architectural rules specific to my projects (via Regex, AST analysis, dependency-cruiser) that runs after the AI has worked. I no longer tell it how to do it, I check that it hasn’t broken the foundations.
But that’s for another chapter: guardrails.