La odisea del contexto
De la sobre-ingeniería a la simplificación radical.
Introducción: la pista falsa del “prompt engineering”
A principios de 2025, mientras mis proyectos crecían, me topé con el muro del contexto. Los modelos olvidaban las reglas, inventaban patrones y rompían mi arquitectura. Mi primera reacción fue de ingeniero: quise construir un sistema de control rígido.
Aquí fue donde surgió mi idea de arquitectura de contexto L0/L1/L2. No era solo una convención de nomenclatura, era un intento de crear un verdadero sistema operativo para IA.
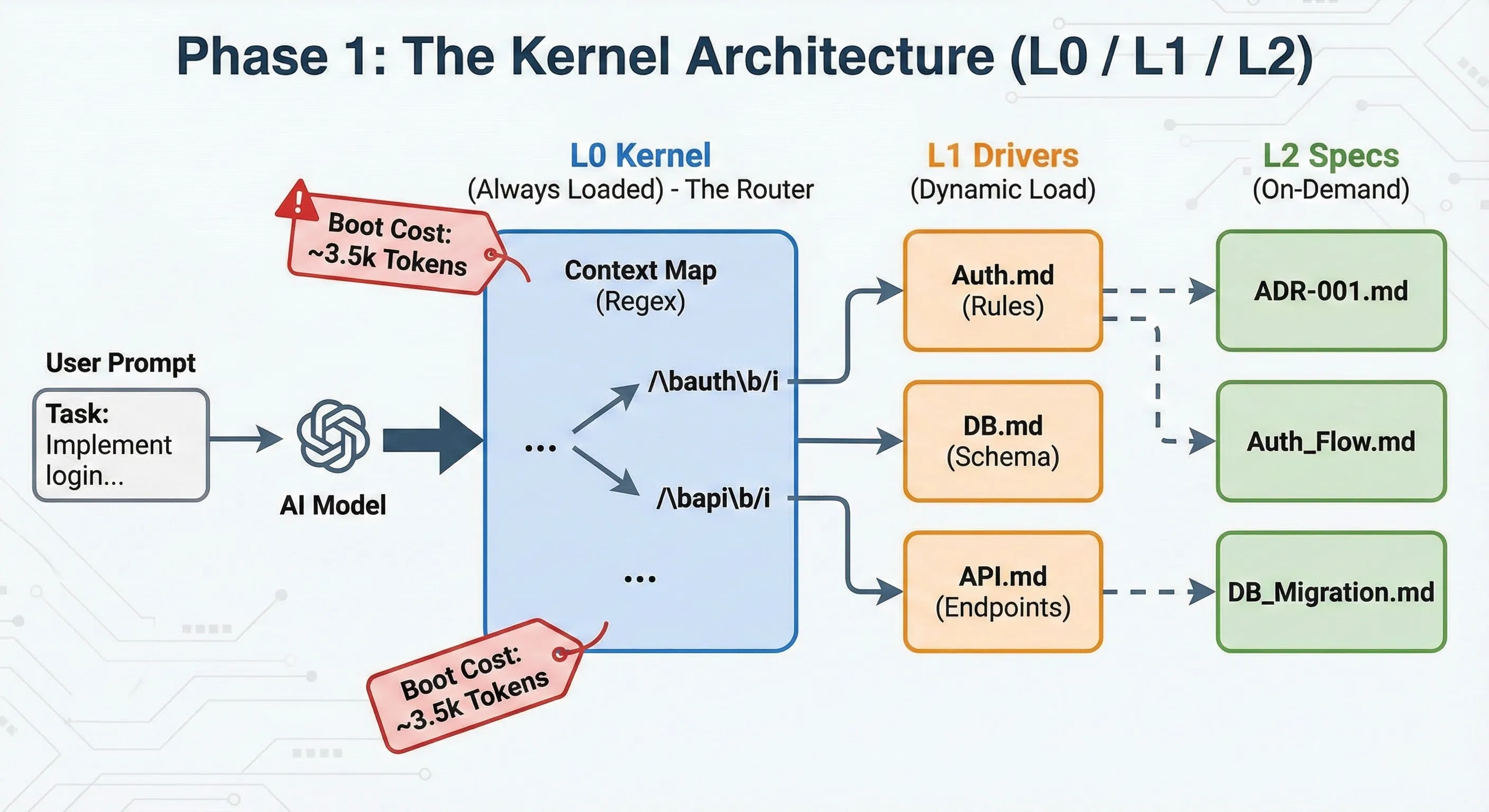
Fase 1: el kernel (L0 / L1 / L2)
La época del control centralizado.
Diseñé una arquitectura jerárquica estricta, inspirada en los niveles de privilegios de sistemas.
- L0 (el kernel): un archivo maestro (
L0.md) cargado permanentemente. Actuaba como un enrutador inteligente que contenía un “context map” basado en regex complejas. Si la IA detectaba la palabraauth, sabía que debía cargar el módulo L1 correspondiente. - L1 (los drivers): las reglas de negocio específicas de un dominio (autenticación, base de datos, API). Estos archivos contenían las restricciones no negociables (
!NEVER commit secrets). - L2 (las especificaciones): la documentación técnica detallada y los ADR (Architecture Decision Records), cargados solo bajo demanda para entender el “porqué”.
El problema: este enfoque funcionaba, pero a un costo prohibitivo. El “arranque” del sistema costaba alrededor de 3.500 tokens en cada interacción, solo para decir “hola”. Además, el mantenimiento del archivo central L0 se convirtió en un cuello de botella: para agregar una funcionalidad, había que modificar el kernel.
Ejemplo del kernel (L0.md):
# L0 KERNEL (ROOT CONTEXT)
## MISSION
Act as a senior software architect and lead developer. Your goal is to produce maintainable, scalable, and secure code following the project's established patterns. You must orchestrate the loading of specialized contexts (L1) based on the task at hand.
## CRITICAL RULES (THE "NEVER" LIST)
1. **NEVER** commit secrets or credentials.
2. **NEVER** bypass the established hexagonal architecture layers.
3. **NEVER** introduce new dependencies without explicit approval (ADR required).
4. **NEVER** write "spaghetti code" (high cyclomatic complexity).
5. **NEVER** ignore linter or type-checker errors.
## L1 CONTEXT MAP (ROUTING TABLE)
| Priority | Pattern (Regex) | L1 Context File | Description | Load Strategy |
| :------- | :-------------- | :-------------- | :---------- | :------------ | --------------- | ------------------------------ | ----------------------------------- | ----------------------------------- | ---- |
| 1 | `/\b(auth | login | signup | session | jwt | oauth)\b/i` | `L1/Auth.md` | Authentication & Security protocols | AUTO |
| 2 | `/\b(db | database | prisma | drizzle | sql | migration)\b/i` | `L1/Database.md` | Data persistence & schema rules | AUTO |
| 3 | `/\b(api | endpoint | route | controller | trpc | graphql)\b/i` | `L1/API.md` | API design & interface standards | AUTO |
| 4 | `/\b(ui | component | tailwind | css | front)\b/i` | `L1/UI.md` | User Interface components & styling | AUTO |
| 5 | `/\b(test | spec | e2e | mock)\b/i` | `L1/Testing.md` | Testing strategies & standards | AUTO |
## OPERATING PROCEDURE
1. **Analyze Task:** Read the user's prompt.
2. **Scan for Patterns:** Match prompt content against the `L1 CONTEXT MAP` regex patterns.
3. **Load L1 Contexts:** For each match, load the corresponding `L1` file.
- _NOTE:_ L1 contexts provide domain-specific constraints and patterns.
4. **Execute:** Perform the task, adhering strictly to L0 rules AND the loaded L1 rules.
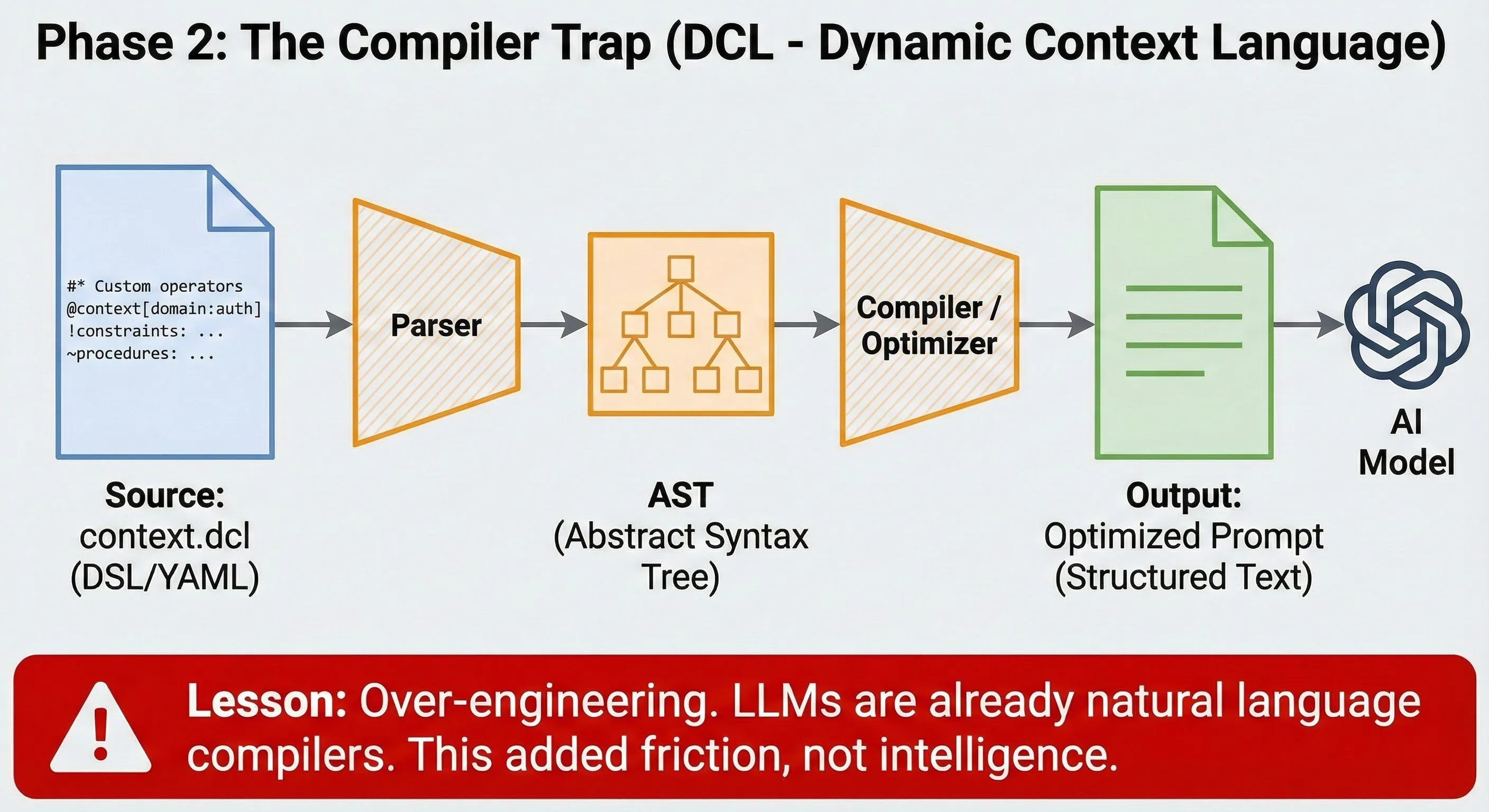
5. **Consult L2 (Optional):** If deep clarification is needed on a specific decision, consult the referenced L2 specs (ADRs) mentioned in the L1 files.Fase 2: la trampa del compilador (Dynamic Context Language)
Cuando el ingeniero quiere ingeniar demasiado.
Frustrado por la imprecisión del lenguaje natural, oscilé hacia el extremo opuesto: tratar el contexto como código. Creé el DCL (Dynamic Context Language).
En lugar de escribir instrucciones, escribía especificaciones en YAML con operadores personalizados:
@context[domain:auth]
!constraints:
never: [commit_secrets, raw_sql]
~procedures:
add_endpoint: [validate, authorize, audit]Incluso construí una pipeline de compilación (Source → AST → Prompt Optimizado). El fracaso productivo: Me di cuenta de que estaba reinventando la rueda. Los LLMs ya son compiladores de lenguaje natural. Forzarlos a leer pseudocódigo añadía fricción sin aumentar la inteligencia. Era sobreingeniería pura.
Ejemplo de DCL:
# ==========================================
# DCL (Dynamic Context Language) - Example
# ==========================================
# Domain: Authentication Module
# ==========================================
# Define el contexto global del dominio
@context[domain:auth]:
# Restricciones estrictas (la IA NUNCA debe hacer esto)
!constraints:
- never: [commit_secrets, raw_sql_queries]
- enforce: [use_orm, secure_password_hashing]
# Dependencias necesarias para este contexto
^dependencies:
- lib: [bcrypt, jsonwebtoken]
- service: [user_service, email_service]
# Procedimientos y patrones a seguir
~procedures:
# Patrón para el registro de usuario
user_signup:
- step: validate_input
desc: "Verificar complejidad de contraseña y formato de email."
- step: hash_password
desc: "Usar bcrypt para hash. Nunca guardar en texto plano."
- step: create_user
desc: "Llamar a user_service para creación en base de datos."
- step: generate_token
desc: "Generar un JWT para la sesión."
- step: send_welcome_email
desc: "Llamar a email_service."
# Patrón para inicio de sesión
user_login:
- step: find_user
desc: "Buscar usuario por email."
- step: verify_password
desc: "Comparar hash con bcrypt."
- step: generate_token
desc: "Generar un nuevo JWT."
# Modelos de datos esperados
#schema:
User:
- id: [uuid, pk]
- email: [string, unique]
- password_hash: [string]
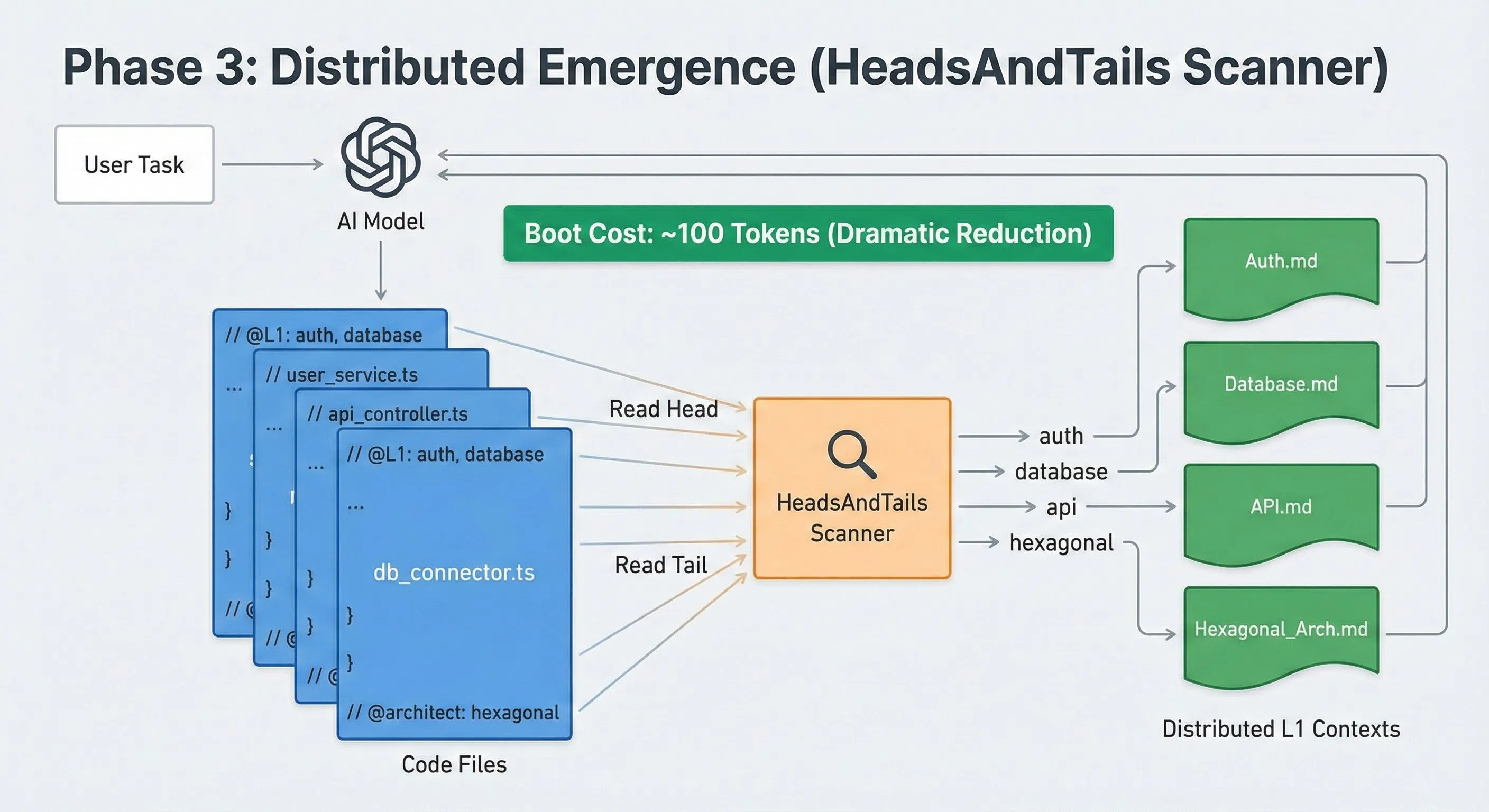
- created_at: [datetime]Fase 3: la emergencia distribuida
El contexto no se carga, emerge.
Entonces eliminé el kernel central por un enfoque distribuido. En lugar de un archivo maestro que lo sabe todo, cada archivo de código declaraba sus propias necesidades a través de etiquetas, como importaciones:
// @L1: auth, api.
Desarrollé un escáner ligero, “HeadsAndTails”, que solo leía el principio y el final de los archivos para descubrir estas etiquetas.
- Ganancia: El costo de arranque pasó de 3.500 a ~100 tokens.
- Filosofía: el contexto ya no se carga de forma centralizada. Se carga bajo demanda, según la tarea y la proximidad del código relevante.
Ejemplo de archivo con etiquetas de contexto:
// ==========================================
// FILE: src/modules/user/core/application/use-cases/CreateUser.ts
//
// @L1: auth, database, domain-events
// @architect: hexagonal/use-case
// ==========================================
import { User } from "../../domain/User";
import { IUserRepository } from "../../ports/IUserRepository";
// ... otras importaciones
export class CreateUserUseCase {
constructor(
private readonly userRepo: IUserRepository,
// ...
) {}
async execute(command: CreateUserCommand): Promise<Result<User>> {
// Lógica de negocio...
// La IA sabe que debe respetar las reglas "auth" y "database"
// porque fueron declaradas en el encabezado.
}
}
// ==========================================
// @security: low-risk
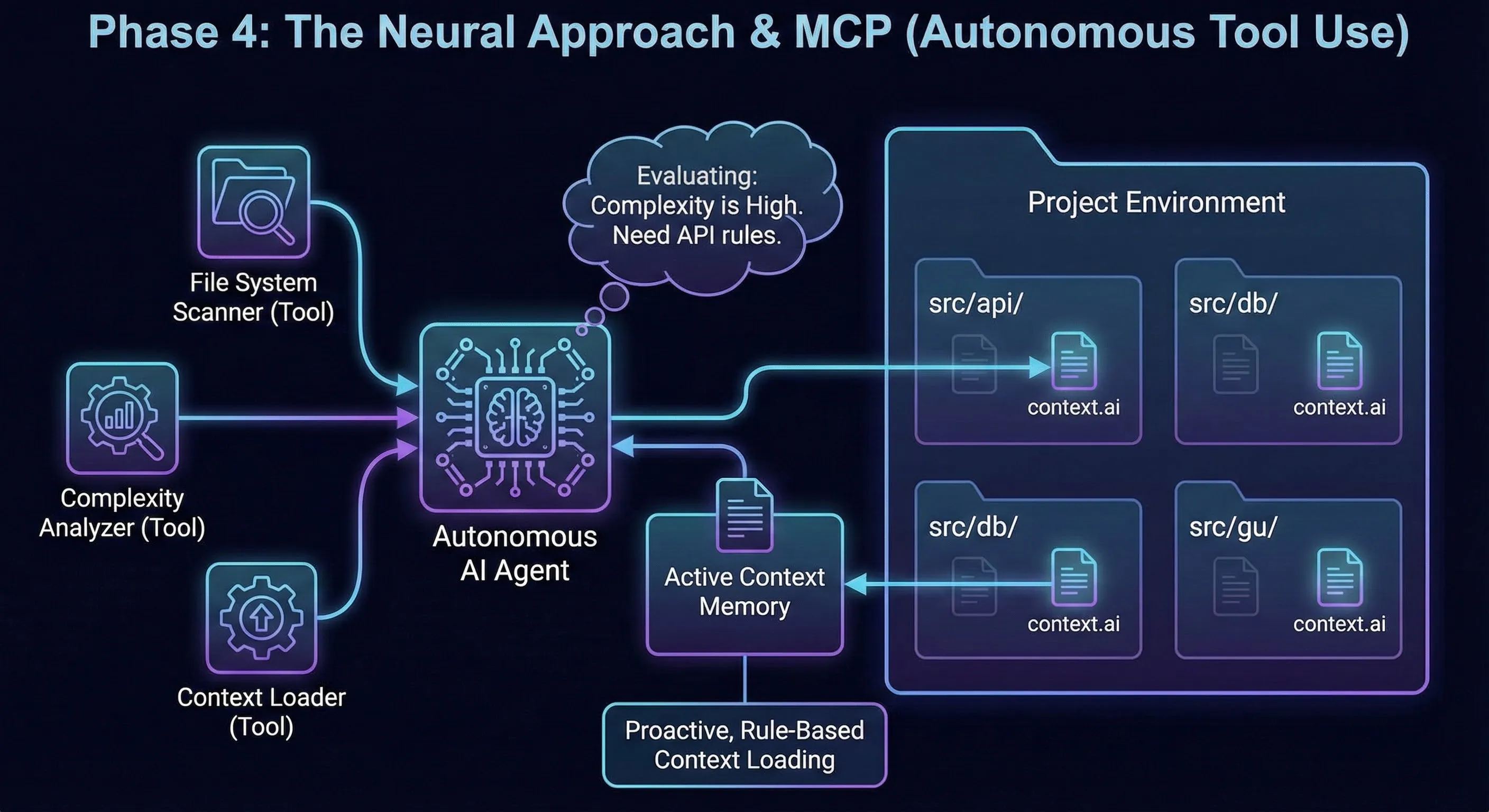
// ==========================================Fase 4: carga bajo demanda con herramientas (AI.md + MCP custom)
De reglas estáticas a recuperación de contexto dirigida.
Esta fase no se suma a las anteriores: dejo de lado los mecanismos previos para probar un nuevo enfoque de context engineering.
Mantengo una base estable que siempre se carga: AI.md. Es la constitución común de todos mis agentes.
En ese archivo defino también un MCP custom (mis tools y sus reglas de uso).
Cuando abro un chat / agente nuevo, ese costo se paga una sola vez: la definición del MCP entra en el contexto inicial.
Después, la carga pasa a ser bajo demanda:
- El agente recibe una tarea (ej: autenticación).
- Llama a mi MCP custom para recuperar el contexto relevante.
- El MCP devuelve los archivos
context.aivinculados al dominio y a los archivos objetivo. - El agente carga solo ese contexto y luego ejecuta.
Punto clave: en mi caso, el MCP sirve para encontrar y cargar el contexto pertinente para la tarea. Ese es el mecanismo que habilita la carga bajo demanda.
Con el tiempo, lo veo claro: eso ya era una forma de RAG casero.
Ejemplo de archivo de contexto (context.ai):
# ==========================================
# LOCATION: src/modules/payment/context.ai
# ==========================================
# Metadatos para el agente
meta:
domain: payment
description: "Reglas críticas para el procesamiento de pagos."
# Reglas de carga condicional
# El agente evalúa estas reglas antes de decidir cargar este contexto.
load_if:
- rule: "Task involves money, transactions, or stripe."
reason: "High risk domain."
- rule: "User explicitly mentions 'payment' or 'checkout'."
reason: "Explicit request."
- rule: "Files being edited are in 'src/modules/payment/'."
reason: "Proximity."
# El contexto en sí, cargado solo si se cumple una regla.
context:
# Restricciones críticas
constraints:
- "NEVER log full credit card numbers or CVV."
- "MUST use the 'PaymentGatewayPort' for all external calls."
- "All transactions MUST be wrapped in a database transaction."
# Patrones de implementación
patterns:
- name: "Idempotency"
description: "Ensure payment requests are idempotent using a unique key."Simulación: el agente con MCP custom en acción
Usuario: “Necesito reembolsar un pago. Es sensible.”
IA (Pensamiento): “Tarea crítica en el dominio
payment. No codifico nada sin verificar las reglas.” IA (Acción MCP):fs_scanner.scan("src/modules/payment", look_for=["context.ai"])IA (Resultado): “Archivocontext.aiencontrado.” IA (Acción MCP):context_loader.load("src/modules/payment/context.ai")IA (Pensamiento): “Contexto cargado. Reglas críticas: usarPaymentGatewayPort, envolver en transacción DB. Ok, puedo empezar el plan.”
Fase 5: el regreso a lo esencial (la constitución)
Madurez y soltar el control.
Hoy reemplacé esa arquitectura por una versión más simple. ¿Por qué? Porque en la época de estas pruebas, los modelos (Claude 4.0 y siguientes) ya eran más inteligentes: buscaban mejor la información y entendían mejor el contexto. Ya no necesitaban que los guiara todo el tiempo; necesitaban sobre todo una constitución.
Mi sistema actual cabe en un solo archivo: AI.md.
Para asegurar la compatibilidad con todas mis herramientas (Cursor, Windsurf, script CLI), utilizo enlaces simbólicos: CLAUDE.md, GEMINI.md, CURSOR.md apuntan todos a este archivo único.
Lo que contiene la constitución (AI.md):
Es un marco de reglas claro, estricto y pragmático:
- Las barandillas (the guardrails): una lista de NEVER y MUST.
- NEVER throw in domain
- NEVER violate layer boundaries
- La arquitectura como ley: la estructura del proyecto no es una sugerencia. El archivo define estrictamente qué tiene derecho a importar cada capa (nada) y cómo se comunican.
- La prevención de la deriva (drift prevention): en lugar de dar órdenes ciegas, explico el porqué.
- “¿Por qué existen estas reglas? Para desacoplar el dominio de la tecnología.”
- Al dar sentido, la IA se adhiere mejor a la restricción.
La arquitectura de la constitución
Una sola fuente de verdad para todos los agentes, cero duplicación.
# Regreso a las bases: Simplicidad
$ ls -l .ai/
-rw-r--r-- 1 user staff 4096 Nov 21 AI.md # La constitución (fuente única)
# Los alias para la compatibilidad de herramientas. Todos apuntan al mismo archivo.
lrwxr-xr-x 1 user staff 5 Nov 21 CLAUDE.md -> AI.md
lrwxr-xr-x 1 user staff 5 Nov 21 CURSOR.md -> AI.md
lrwxr-xr-x 1 user staff 5 Nov 21 GEMINI.md -> AI.mdExtracto de la constitución (AI.md):
# Constitution
## TL;DR (The "NEVER" List)
**NEVER:**
- Mute lint/type errors (fix root causes)
- Violate layer boundaries (core→npm, application→infrastructure)
- Throw in domain/application (return `Result<T, E>`)
## Principles & Rationale (Drift Prevention)
**Why these rules exist:**
1. **Architecture**: We decouple the _core domain_ from _technology_...
...Conclusión: la lección de la obsolescencia
Balance
Ya no busco “pilotar” la IA al microsegundo con compiladores o enrutadores complejos. Le doy una brújula (AI.md), un mapa (la estructura de carpetas), y la dejo navegar.
El código es mejor, mi mente está más libre, y el sistema es finalmente estable. Menos es más.
Sensación unos meses después
Releyendo este recorrido unos meses después, algo me impacta: algunas de estas construcciones hoy son obsoletas (es el precio del aprendizaje en un campo que evoluciona rápido).
Todo este trabajo (el kernel L0, el compilador DCL, el escáner de etiquetas) fue superado por la mejora constante de los modelos y la llegada de nuevos estándares. Es la ley de este dominio: construimos puentes temporales esperando que la tecnología nos permita volar.
Pero no fue tiempo perdido. Fue el aprendizaje necesario para entender lo que realmente importa: la arquitectura y las restricciones de negocio.
He limpiado y publicado el código de esta exploración en código abierto: ai-context-layers. Es un archivo educativo de las Fases 1 a 4, no un producto mantenido, pero los patrones y el compilador DCL pueden servir de inspiración.
¿Qué sigue?
Mi lógica ha evolucionado. Dado que ya no puedo (y no necesito) controlar todo a priori en el prompt, me concentro en la validación a posteriori.
Mi nuevo proyecto es la creación de un validador personalizado. No solo un linter, sino un motor de reglas arquitectónicas específicas para mis proyectos (vía Regex, análisis AST, dependency-cruiser) que corre después de que la IA ha trabajado. Ya no le digo cómo hacerlo, verifico que no haya roto los cimientos.
Pero ese es el tema de otro capítulo: las barandillas.