Orquestar lo esencial
Aligerar los MCP, orquestar agentes y colocar rieles de calidad.
Otoño 2025 : orquestación de agentes
Cambiar de postura
Durante años, mi placer era “devorar código”. Eso sigue siendo cierto. Pero hoy, el código solo ya no es un diferenciador: todos podemos codificar, y las IAs también. Lo que cuenta para mí es pensar la necesidad: decidir qué hacer, qué automatizamos, cómo controlamos. La IA no reemplaza al desarrollador: amplifica la postura del desarrollador. Si la mentalidad es “yo piloto, yo verifico, yo orquesto”, los modelos se convierten en aceleradores fiables. Si la mentalidad es “copio/pego”, se convierten en generadores de deuda.
Dediqué cientos de horas a probar. A veces empujé demasiado lejos, a veces retrocedí. No es un hueco en mi CV: es una inversión. Construyo, observo, ajusto. La IA cambia cómo aprendo y cómo pruebo; no piensa por mí, me acelera. Y eso me llevó de forma natural a orquestar en lugar de escribir todo yo mismo.
Por qué la orquestación de agentes
Cuando Claude Code introdujo los sub-agentes con contexto separado (ventana dedicada, herramientas/configuración propias) que ejecutan, rinden un informe y luego parten de cero, primero quise “hacer las cosas bien”. Al día siguiente del lanzamiento, creo un meta-agente cuyo único rol es leer la documentación oficial… y generar otros agentes bajo demanda.
En una tarde, me encuentro con una treintena de agentes especializados: front-end generalista, front-end “UI state”, front-end “accesibilidad”, back-end, base de datos, “diagnóstico pruebas”, “probador Playwright”, “lint/format”, “triage CI”, “escritor doc”, etc.
Sobre el papel, parece un equipo ideal. En realidad, recreo la ceremonia que me inculcaron en las empresas: “cliente → PO → arquitecto → dev → tester → reviewer → tech lead → humano”.
Y ahí, contragolpe:
- cada sub-agente vive en su propia burbuja y olvida todo una vez terminada su tarea;
- si el agente principal no transmite la información perfectamente al agente correcto, caemos en el escenario del “teléfono descompuesto”;
- la fricción aumenta (demasiados pasos, demasiados mensajes), la calidad baja (pérdidas de info, repeticiones, malentendidos).
Me doy cuenta de que caí en la trampa de la sobre-organización. Quería crear un equipo ideal, creé una burocracia.
Entiendo entonces que multiplicar los agentes no basta. El reto no es tener 30 ejecutantes, sino tener una visión de conjunto coherente y reglas del juego explícitas.
Corto por lo sano para volver a lo esencial:
- menos agentes, mejor definidos;
- el agente principal retomando claramente su rol de orquestador;
- mi rol: poner los rieles (perímetros, reglas, validaciones, orden de paso) e intervenir en el momento justo.
Pregunta abierta (que va más allá de la IA): si demasiadas ceremonias terminan perjudicando la señal entre los agentes, ¿no estamos reproduciendo a veces la misma deriva en ciertas organizaciones humanas “demasiado ágiles”?
Mi flujo de orquestación (versión mediados de octubre 2025)
A lo largo de estas pruebas, convergí hacia algo mucho más simple:
- menos agentes, más consignas,
- un solo “orquestador” principal,
- y dos comandos muy simples:
/issuepara hablar con GitHub (crear/actualizar/comentar issues),/worktreepara crear copias de trabajo paralelas (una por sub-tarea).
Probé un enfoque muy avanzado con muchos scripts, logs y pruebas end-to-end… y terminé dejándolo: demasiado frágil, demasiado complicado para el valor que aportaba.
Hoy, la orquestación cabe en un solo prompt reutilizable (comando/skill): un texto que describe el flujo de trabajo esperado, los pasos, las acciones posibles y cuándo llamar a /issue o /worktree.
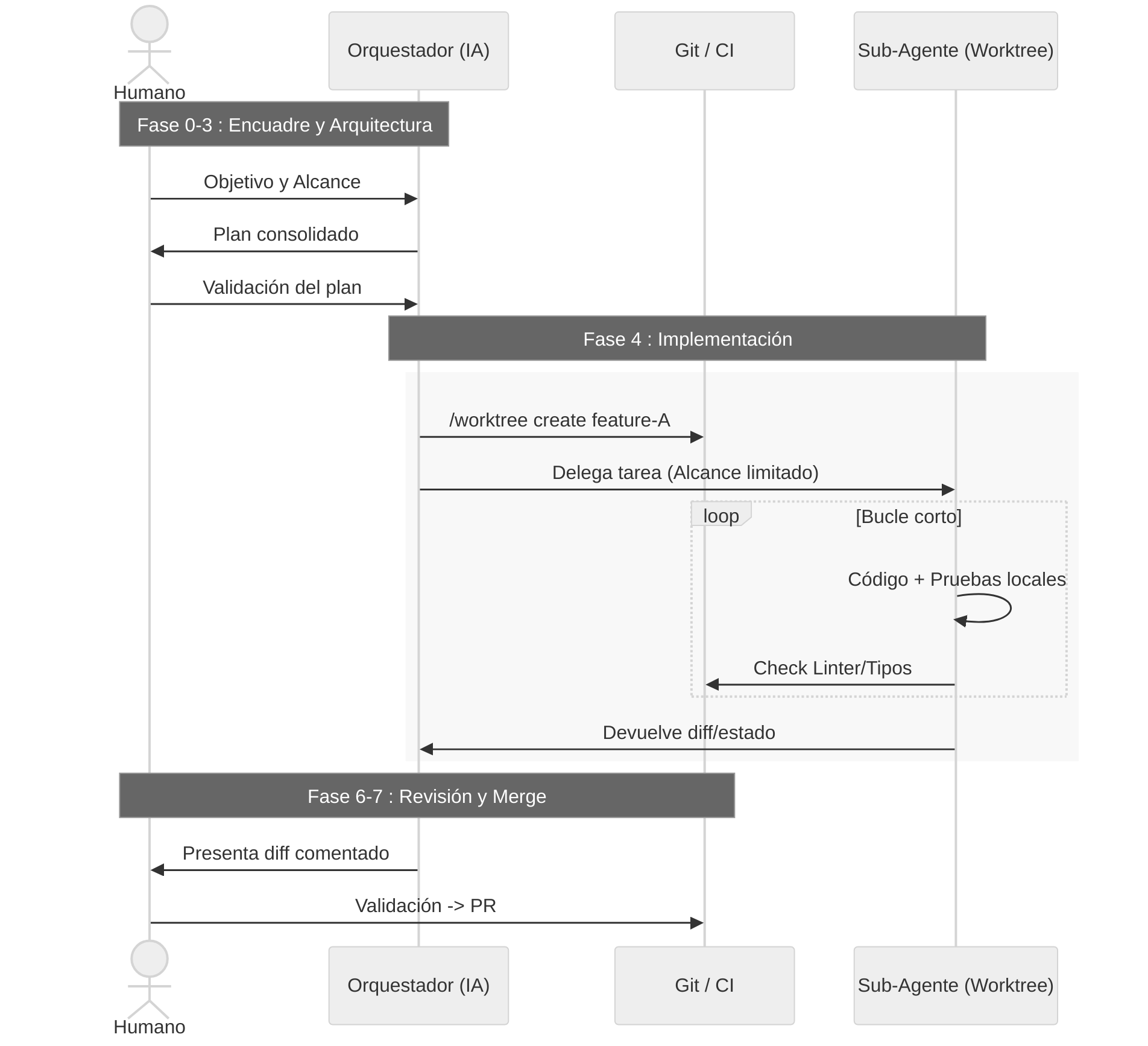
Mi flujo de orquestación se parece a esto:
- Fase 0 : Alineación humano ↔ orquestador. Nos ponemos de acuerdo en unos pocos mensajes sobre el objetivo, el alcance y qué significa “terminado”.
- Fase 1 : Exploración dirigida. El orquestador lee el proyecto, recorre la documentación y las señales de pruebas, y me resume lo que entendió.
- Fase 2 : Refinamiento con el humano. Me vuelve a hacer las preguntas correctas, ajustamos las restricciones, resolvemos ambigüedades.
- Fase 3 : Arquitectura. El orquestador propone uno o varios enfoques (a veces haciendo intervenir 1 o 2 “arquitectos” especializados), luego me somete un plan consolidado.
- Fase 4 : Implementación.
- Para una tarea simple: un solo agente trabaja en una copia de trabajo dedicada.
- Para una tarea compleja: el orquestador divide en sub-tareas, crea varias copias de trabajo y delega a varios agentes, cada uno en su trozo.
- Fase 5 : Pruebas. Las pruebas, el lint, las verificaciones de tipo y de arquitectura se lanzan del lado de los agentes; los problemas se corrigen en bucle corto.
- Fase 6 : Revisión. El orquestador me presenta un diff comentado; releo, comento, pido correcciones si es necesario.
- Fase 7 : PR. Se crea una pull request con el contexto, una checklist y un enlace a los issues concernidos.
Los principios clave siguen siendo simples:
- pocos agentes, justo lo bastante especializados;
- un desglose del trabajo y del contexto;
- contratos explícitos entre los pasos;
- la menor fricción posible (suficiente para garantizar la calidad, no más);
- comandos
/issuey/worktreeobservables (logs sobrios), pero sin glue code inútil.
Crash test de la sobre-orquestación
A la inversa, otro proyecto me muestra lo que pasa cuando voy demasiado lejos en la orquestación de IA.
A principios de octubre, decido poner todo en sub-comandos: gestión de ramas, worktrees, issues, PRs, con hooks, guardias, flujos “seguros” y scripts que envuelven lo que Git ya sabe hacer.
Sobre el papel, es tranquilizador: todo está encuadrado, todo pasa por rieles caseros. En la práctica, paso días:
- peleando con problemas de rutas y portabilidad;
- apilando scripts difíciles de depurar;
- documentando una complejidad que yo mismo creé.
El ratio “energía gastada / valor creado” se vuelve malo. Este enfoque no era sostenible en el tiempo.
El 1 de noviembre, hago una primera dieta:
- elimino docenas de comandos especializados;
- tiro scripts que duplicaban Git sin beneficio real;
- reduzco la documentación que solo compensaba la complejidad.
Unos días más tarde, hago una segunda pasada:
- corto de nuevo “habilidades” y documentos, a veces en un 70% o más;
- formalizo principios simples:
- una habilidad debe orquestar, no describir toda la estrategia;
- se supone que el agente es inteligente, no necesita 800 líneas de ejemplos;
- empezamos pequeño, eliminamos lo que no sirve;
- iteramos sobre necesidades reales, no sobre “por si acaso”.
Este repositorio se convierte para mí en la prueba concreta de que:
- demasiada abstracción puede costar más de lo que aporta;
- la documentación no es un antídoto contra la mala arquitectura;
- la decisión correcta no es siempre “añadir una capa”, sino a veces quitar una capa.
El repo asociado está aquí: claude-code-plugins/orchestration. El repo está mantenido, y los workflows evolucionan constantemente.