Orchestrer l'essentiel
Orchestrer des agents, du workflow aux sous-agents.
Automne 2025 : orchestration d’agents
Changer de posture
Pendant des années, mon plaisir c’était de “bouffer du code”. Ça reste vrai. Mais aujourd’hui, le code seul n’est plus un différenciateur : on peut tous coder, et les IA aussi. Ce qui compte pour moi, c’est penser le besoin : décider quoi faire, ce qu’on automatise, comment on contrôle. L’IA ne remplace pas le développeur : elle amplifie la posture du développeur. Si le mindset est “je pilote, je vérifie, j’orchestre”, les modèles deviennent des accélérateurs fiables. Si le mindset est “je copie/colle”, ils deviennent des générateurs de dettes.
J’ai consacré des centaines d’heures à tester. Parfois j’ai poussé trop loin, parfois j’ai fait marche arrière. Ce n’est pas un trou dans mon CV : c’est un investissement. Je construis, j’observe, j’ajuste. L’IA change ma manière d’apprendre et d’essayer ; elle ne pense pas à ma place, elle m’accélère. Et ça m’a logiquement amené à orchestrer plutôt qu’à tout écrire moi-même.
Pourquoi l’orchestration d’agents
Quand Claude Code a introduit les sous-agents avec contexte séparé (fenêtre dédiée, outils/config propres) qui exécutent, rendent un rapport puis repartent à zéro, j’ai d’abord voulu “faire les choses bien”. Dès le lendemain de la release, je crée un méta-agent dont l’unique rôle est de lire la doc officielle… et de générer d’autres agents à la demande.
En une soirée, je me retrouve avec une trentaine d’agents spécialisés : front-end généraliste, front-end “UI state”, front-end “accessibilité”, back-end, base de données, “diagnostic tests”, “testeur Playwright”, “lint/format”, “CI triage”, “doc writer”, etc.
Sur le papier, ça ressemble à une équipe idéale. En réalité, je recrée la cérémonie qu’on m’a inculquée en entreprise : “client → PO → architecte → dev → testeur → reviewer → tech lead → humain”.
Et là, retour de bâton :
- chaque sous-agent vit dans sa propre bulle et oublie tout une fois sa tâche terminée ;
- si l’agent principal ne transmet pas parfaitement l’information au bon agent, on tombe dans le scénario du “téléphone arabe” ;
- la friction augmente (trop d’étapes, trop de messages), la qualité baisse (pertes d’infos, redites, malentendus).
Je réalise que je suis tombé dans le piège de la sur-organisation. Je voulais créer une équipe idéale, j’ai créé une bureaucratie.
Je comprends alors que multiplier les agents ne suffit pas. L’enjeu n’est pas d’avoir 30 exécutants, mais d’avoir une vision d’ensemble cohérente et des règles du jeu explicites.
Je taille dans le gras pour revenir à l’essentiel :
- moins d’agents, mieux découpés ;
- l’agent principal qui reprend clairement son rôle d’orchestrateur ;
- mon rôle à moi : poser les rails (périmètres, règles, validations, ordre de passage) et intervenir au bon moment.
Question ouverte (qui dépasse l’IA) : si trop de cérémonies finissent par nuire au signal chez les agents, est-ce qu’on ne reproduit pas parfois la même dérive dans certaines organisations humaines “trop agiles” ?
Mon workflow d’orchestration (version mi-octobre 2025)
Au fil de ces essais, j’ai convergé vers quelque chose de beaucoup plus simple :
- moins d’agents, plus de consignes,
- un seul “orchestrateur” principal,
- et deux commandes très simples :
/issuepour parler à GitHub (créer/mettre à jour/commenter des issues),/worktreepour créer des copies de travail parallèles (une par sous-tâche).
J’ai testé une approche très poussée avec beaucoup de scripts, de logs, de tests end-to-end… puis je l’ai abandonnée : trop fragile, trop compliquée pour ce qu’elle apportait.
Aujourd’hui, l’orchestration tient dans un seul prompt réutilisable (commande/skill) : un texte qui décrit le workflow attendu, les étapes, les actions possibles et quand appeler /issue ou /worktree.
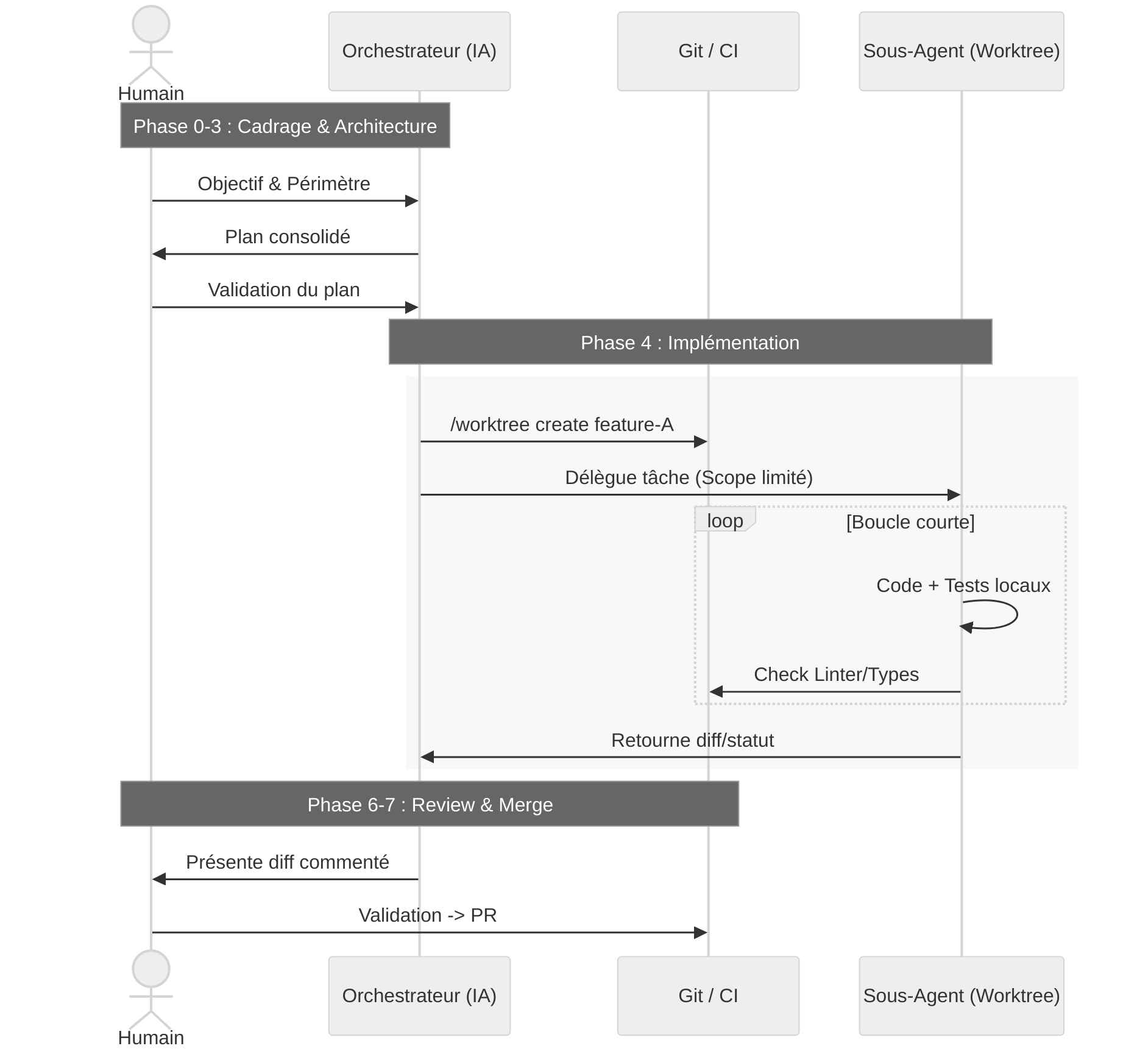
Mon workflow d’orchestration ressemble à ça :
- Phase 0 : Alignement humain ↔ orchestrateur. On se met d’accord en quelques messages sur l’objectif, le périmètre et ce que “fini” veut dire.
- Phase 1 : Exploration ciblée. L’orchestrateur lit le projet, parcourt la documentation et les signaux de tests, et me résume ce qu’il a compris.
- Phase 2 : Affinage avec l’humain. Il me repose les bonnes questions, on ajuste les contraintes, on tranche les ambiguïtés.
- Phase 3 : Architecture. L’orchestrateur propose une ou plusieurs approches (parfois en faisant intervenir 1 ou 2 “architectes” spécialisés), puis me soumet un plan consolidé.
- Phase 4 : Implémentation.
- Pour une tâche simple : un seul agent travaille dans une copie de travail dédiée.
- Pour une tâche complexe : l’orchestrateur découpe en sous-tâches, crée plusieurs copies de travail et délègue à plusieurs agents, chacun sur son morceau.
- Phase 5 : Tests. Les tests, le lint, les vérifications de type et d’architecture sont lancés côté agents ; les problèmes sont corrigés en boucle courte.
- Phase 6 : Review. L’orchestrateur me présente un diff commenté ; je relis, je commente, je demande des corrections si besoin.
- Phase 7 : PR. Une pull request est créée avec le contexte, une checklist et un lien vers les issues concernées.
Les principes clés restent simples :
- peu d’agents, juste assez spécialisés ;
- un découpage du travail et du contexte ;
- des contrats explicites entre les étapes ;
- le moins de friction possible (assez pour garantir la qualité, pas plus) ;
- des commandes
/issueet/worktreeobservables (logs sobres), mais pas de glue code inutile.
Crash‑test de la sur‑orchestration
À l’opposé, un autre projet me montre ce qui se passe quand je vais trop loin dans l’orchestration d’IA.
Début octobre, je décide de tout mettre dans des sous‑commandes : gestion des branches, des worktrees, des issues, des PR, avec des hooks, des guards, des workflows “sécurisés” et des scripts qui wrapent ce que Git sait déjà faire.
Sur le papier, c’est rassurant : tout est encadré, tout passe par des rails maison. En pratique, je passe des jours à :
- me battre avec des problèmes de chemins et de portabilité ;
- empiler des scripts difficiles à debugger ;
- documenter une complexité que j’ai moi‑même créée.
Le ratio “énergie dépensée / valeur créée” devient mauvais. Cette approche n’était pas tenable dans la durée.
Le 1er novembre, je fais une première cure d’amaigrissement :
- je supprime des dizaines de commandes spécialisées ;
- je jette les scripts qui dupliquaient Git sans réel bénéfice ;
- je réduis la documentation qui ne faisait que compenser la complexité.
Quelques jours plus tard, je fais une deuxième passe :
- je coupe encore des “skills” et des documents, parfois de 70 % ou plus ;
- je formalise des principes simples :
- un skill doit orchestrer, pas décrire toute la stratégie ;
- l’agent est supposé intelligent, il n’a pas besoin de 800 lignes d’exemples ;
- on commence petit, on supprime ce qui ne sert pas ;
- on itère sur des besoins réels, pas sur des “au cas où”.
Ce dépôt devient pour moi une preuve concrète que :
- trop d’abstraction peut coûter plus cher que ce que ça apporte ;
- la documentation n’est pas un antidote à une mauvaise architecture ;
- la bonne décision n’est pas toujours “ajouter une couche”, mais parfois supprimer une couche.
Le repo associé est ici : claude-code-plugins/orchestration. Le repo est maintenu, et les workflows évoluent constamment.